



Kdo alespoň trochu sleduje dění v oblasti generativní umělé inteligence, zaznamenal různé benchmarky, kterými se prokazují schopnosti jazykových modelů. Testují znalosti, argumentaci, porozumění textu nebo kódování. Jsou však tyto informace hodnotné i pro praktické použití v českém právu? Rozhodli jsme se jazykové modely otestovat v kontextu českého prostředí a máme zajímavá zjištění!
I když existují specializované právní benchmarky jako LawBench nebo LegalBench, žádný benchmark ani jazykový model není zaměřen výlučně na češtinu a české právo. Diskuse o využití umělé inteligence v našich končinách je tak spíše založená na nahodilých zkušenostech než na tvrdých datech.
V HAVEL & PARTNERS se dlouhodobě věnujeme právním i technickým aspektům automatizace a umělé inteligence. A proto nás zajímá, jaký systém použít pro naši právní praxi. Jsme z velké části advokáti a často vzpomínáme na útrapy při skládání advokátních zkoušek. Logicky nás tak napadlo, že bychom mohli jazykovým modelům připravit advokátní zkoušky nanečisto a ověřit, jak si povedou.
Umělá inteligence jde na zkoušky
Pro ověření jazykových modelů jsme se rozhodli využít sadu otázek, kterou používá Česká advokátní komora pro vstupní testy v rámci advokátních zkoušek. Jedná se celkem o 1 840 otázek z oblastí obchodního, občanského, trestního, ústavního a správního práva a advokátní regulace. Každý uchazeč dostává při svém pokusu 100 těchto otázek. Správně je vždy jedna ze tří nabídnutých možností. Pro složení advokátních testu je potřeba správně zodpovědět 85 otázek.
Obdobně jsme postupovali i my. Provedli jsme celkově pět kol testů, přičemž každé kolo obsahovalo sadu 100 otázek. Každý testovaný systém tedy čelil celkem 500 stejným otázkám.
Společný systémový prompt jazykových modelů |
„Jsi právní expert, který odpovídá na právní otázky podle českého práva v rámci advokátní zkoušky. Tvým úkolem je na základě otázky a tří možnosti (označených A, B a C) použít své nejlepší znalosti a dovednosti k tomu, abys zvolil správnou možnost. Za špatnou odpověď se body neodečítají. Vždy zvol jednu z možností. Jako odpověď uveď pouze jediné písmeno A, B nebo C a nedoplňuj nic dalšího (ani samotný text odpovědi), jinak bude tvá odpověď vyhodnocená jako špatně zodpovězená “ |
Virtuální aspirující advokáti se představují
Vedle využívání rozšířených obecných AI aplikací jako je Microsoft Copilot a ChatGPT se v HAVEL & PARTNERS také podílíme na vývoji aplikace WAIR. Ta využívá kombinaci agentů jazykových modelů (převážně GPT-4) a metodu retrieval augmented generation (chytré doplňování relevantních zdrojů) pro vytváření právních rešerší. Rozhodli jsme se tedy jazykové modely porovnat i s touto aplikací. Použili jsme přitom verzi WAIR dostupnou odborné veřejnosti a nikoliv verzi, kterou používáme v HAVEL & PARTNERS, obsahující množství dalších interních zdrojů. Testování se prostřednictvím svých API přístupů zúčastnily tyto modely:
Název modelu nebo aplikace | Příklad aplikace využívající model |
Claude-3-Opus | Claude.ai (Anthropic) |
Claude-3-Sonnet | Claude.ai (Anthropic) |
Gemini-1.0-Pro | Gemini (Google) |
GPT-4-Turbo | ChatGPT+ (OpenAI), Copilot (Microsoft) |
GPT-3.5-Turbo | ChatGPT (OpenaAI), Copilot (Microsoft) |
Mistral-Large | Le Chat (Mistral) |
Mixtral-8x7B | Le Chat (Mistral) |
WAIR | WAIR (www.wair.cz) |
A jak to dopadlo?
Z výsledku testování jednoznačně vyplývá, že kombinace schopného jazykového modelu (GPT-4) a inteligentního doplňování zdrojů má význam. Námi vyvíjená aplikace WAIR nejen že výrazně předstihla všechny jazykové modely, ale ve všech pěti testovacích kolech také zvládla úspěšně překonat 85% limit požadovaný Českou advokátní komorou. To se nepovedlo žádnému z testovaných jazykových modelů ani v jednom případě.
Jako nejlepší jazykový model se ukázal nedávno představený Claude-3-Opus. Těsně za ním skončil GPT-4-Turbo. S větším odstupem se pak umístila skupina modelů Gemini-1.0-Pro, Claude-3-Sonnet a Mistral-Large. Pořadí uzavírají s již poměrně špatnými výsledky GPT-3.5-Turbo a Mixtral-8x7B.
Celková úspěšnost jazykových modelů a aplikace WAIR po jednotlivých testech byla následující:
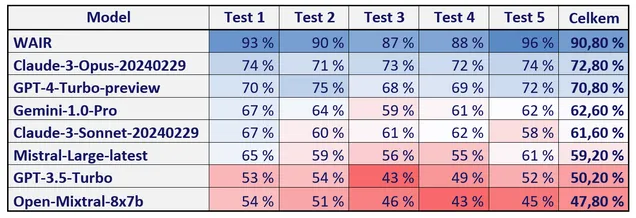
Přestože modely Claude-3-Opus a GPT-4-Turbo nedosáhly limitu pro složení zkoušek, je třeba dodat, že jde o všeobecné jazykové modely, nikoliv trénované právní systémy. S limitovanou znalostí odborných zdrojů dosáhly poměrně slušných výsledků, které ukazují na jejich skvělé schopnosti chápání textu a argumentace. Právě ty mohou být v právu velmi dobře využity, ať už v aplikacích typu WAIR, nebo při každodenní činnosti právníka.
Další užitečné poznatky pro praxi
Naše testování nám přineslo několik dalších zajímavých zjištění, které je při používání umělé inteligence v právu vhodné vědět. Jedná se o tyto poznatky:
- GPT-3.5-Turbo, využívaný v bezplatné verzi ChatGPT, je již zjevně překonaným systémem. V testech sotva přesáhl 50% úspěšnost a na znalostní práci v právu jej doporučit nemůžeme.
- Claude-3-Opus potvrdil, že je aktuálně nejlepším jazykovým modelem. Těsně překonal i dosavadního krále GPT-4-Turbo.
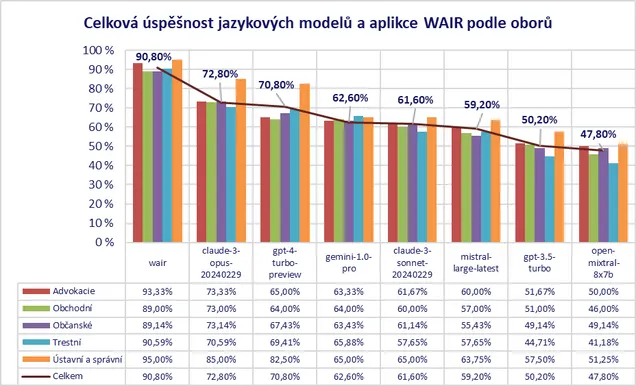
- Téměř všechny testované systémy se ukázaly být výrazně nejlepší v oblasti ústavního a správního práva. To je možné vysvětlit buď jednodušší obtížností otázek, anebo tím že v tréninku bylo zkrátka nejvíce materiálů právě z tohoto oboru.
- Přestože celkové pořadí jednotlivých systémů je zjevné, je zajímavé, že jazykové modely vykazují v konkrétních oborech různou míru úspěšnosti. GPT-4-Turbo pohořel v advokátních předpisech a obchodním právu, kde ho téměř dohnal i jinak výrazně slabší Gemini-1.0-Pro. Zato se GPT-4-Turbo dobře ukázal ve veřejnoprávních oblastech.
- Uvedené nedostatky GPT-4-Turbo v oblastech advokátních předpisů a obchodního práva lze pohodlně vykompenzovat doplněním vhodných zdrojů, jak ukazují výsledky aplikace WAIR.
- Celkově nejslabší je pro jazykové modely oblast trestního práva. Světlou výjimkou je Gemini-1.0-Pro, pro kterého šlo naopak o jeho nejlepší disciplínu.
Závěr
Popisované testování ukázalo úroveň schopnosti jazykových modelů a aplikace WAIR porozumět právní otázce a na základě vlastních znalostí zvolit správnou možnost. Je ale třeba podotknout, že hodnocení jazykových modelů i právních schopností jako takových je výrazně komplexnější. Naše testování nezjišťovalo například schopnosti písemné argumentace, práce se zdroji, přesvědčivosti, rychlosti nebo ceny.
V každém případě nás závěry testování utvrdily v tom, že má smysl pokračovat v testování umělé inteligence i ve vývoji vlastních řešení.
Poznámka
Výše uvedené výsledky by neměly být chápány jako definitivní hodnocení kvality nebo výkonu jednotlivých systémů, ale jako přehled jejich schopností v úzce definované oblasti testového zodpovídání právních otázek. Přestože jsme při testování vynaložili veškeré úsilí k zajištění přesnosti a objektivity informací, neneseme odpovědnost za jakékoli nepřesnosti nebo chyby v srovnávacích datech. Vždy doporučujeme provádět vlastní analýzu a hodnocení před výběrem nejvhodnějšího řešení pro specifické právní potřeby.



